Abstract
The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts, while retaining strong generalization across tasks.





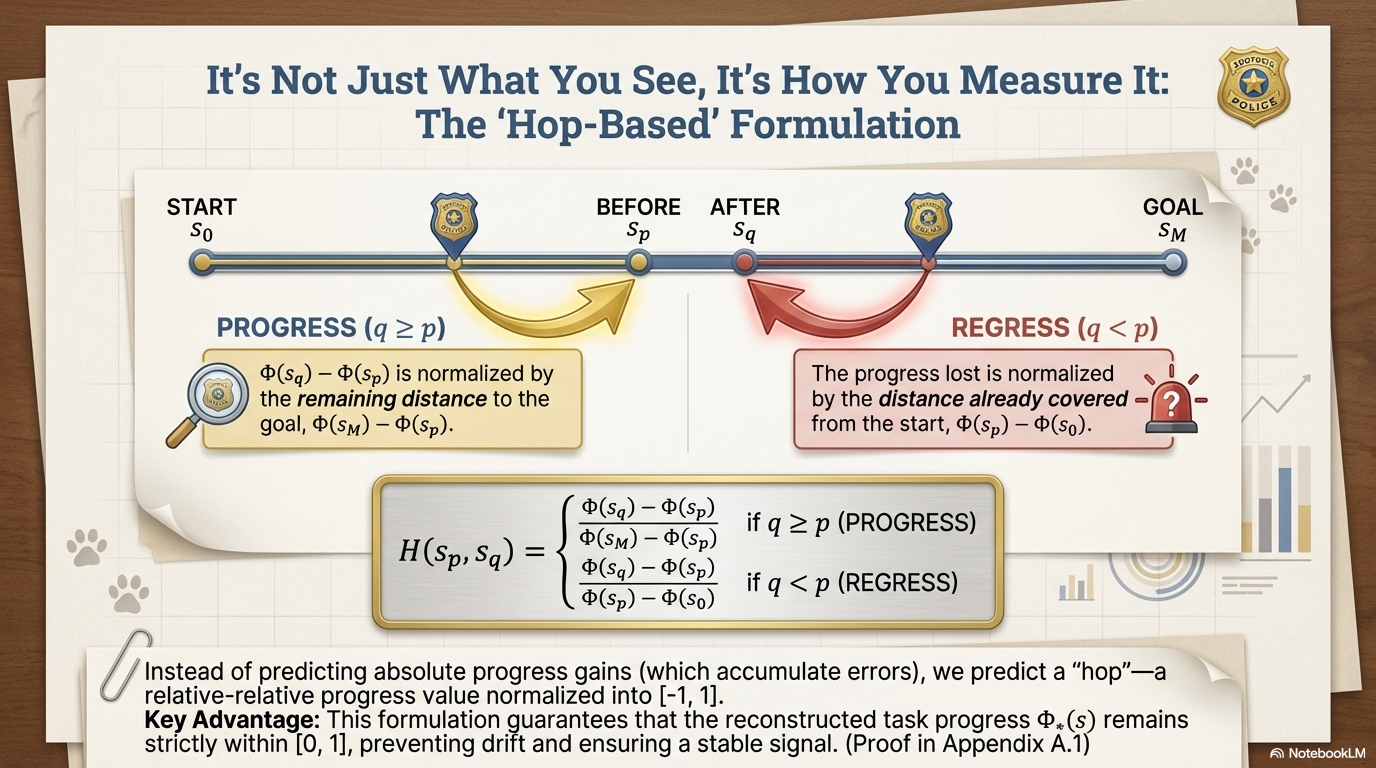

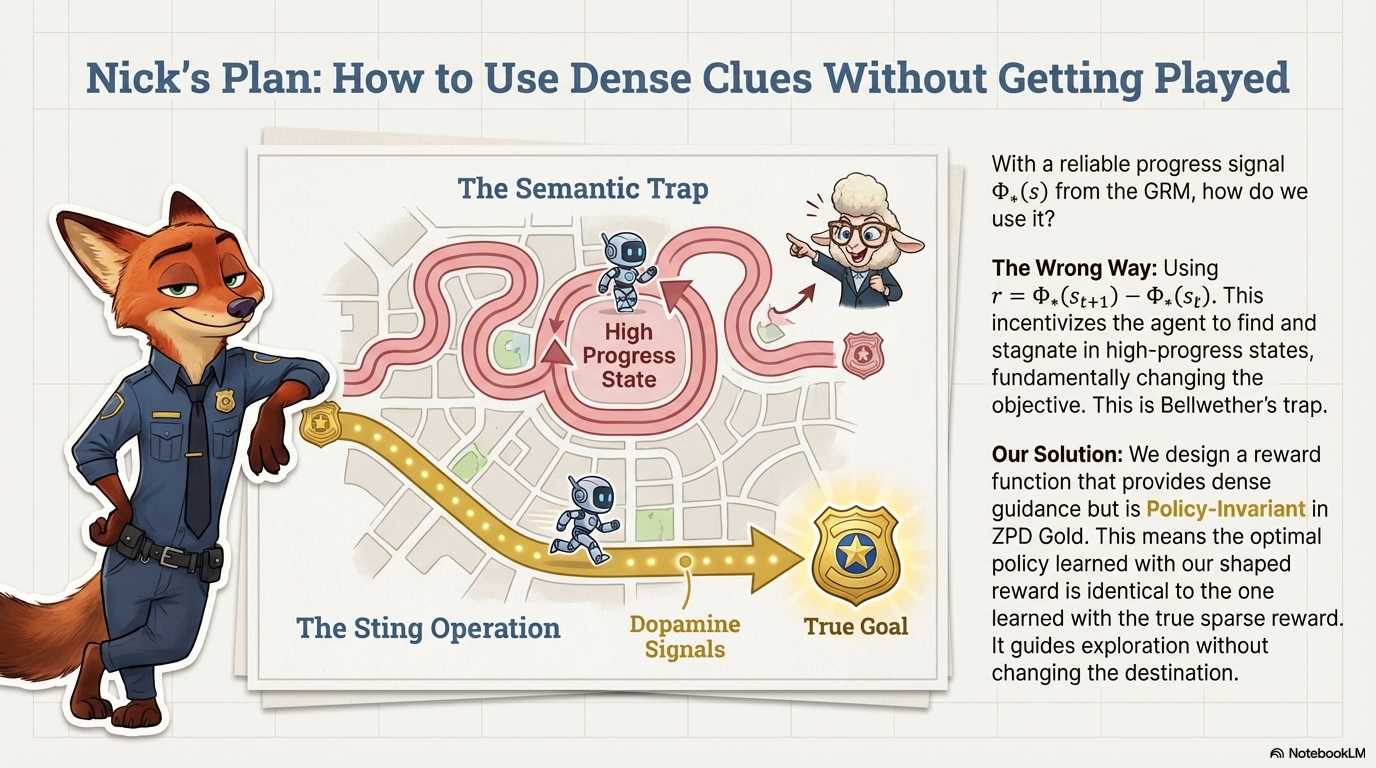

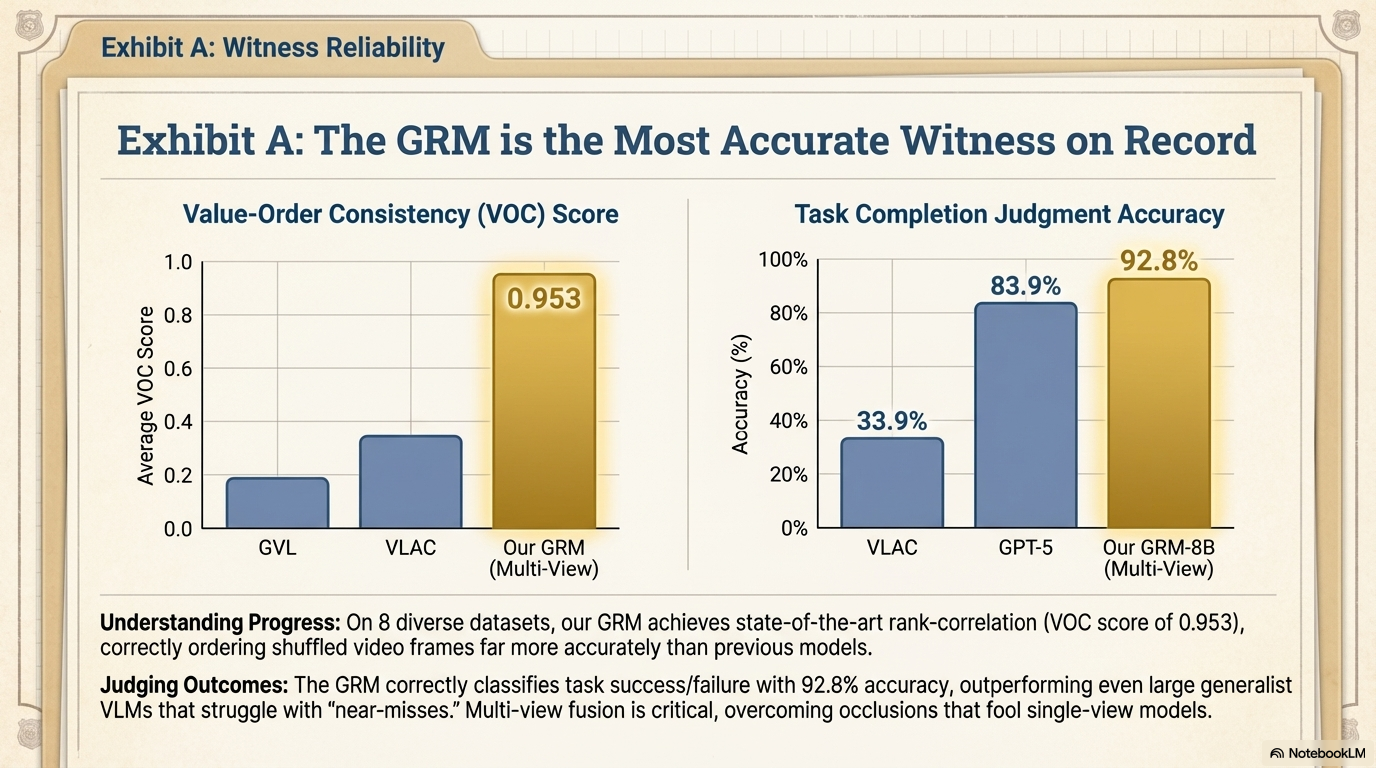
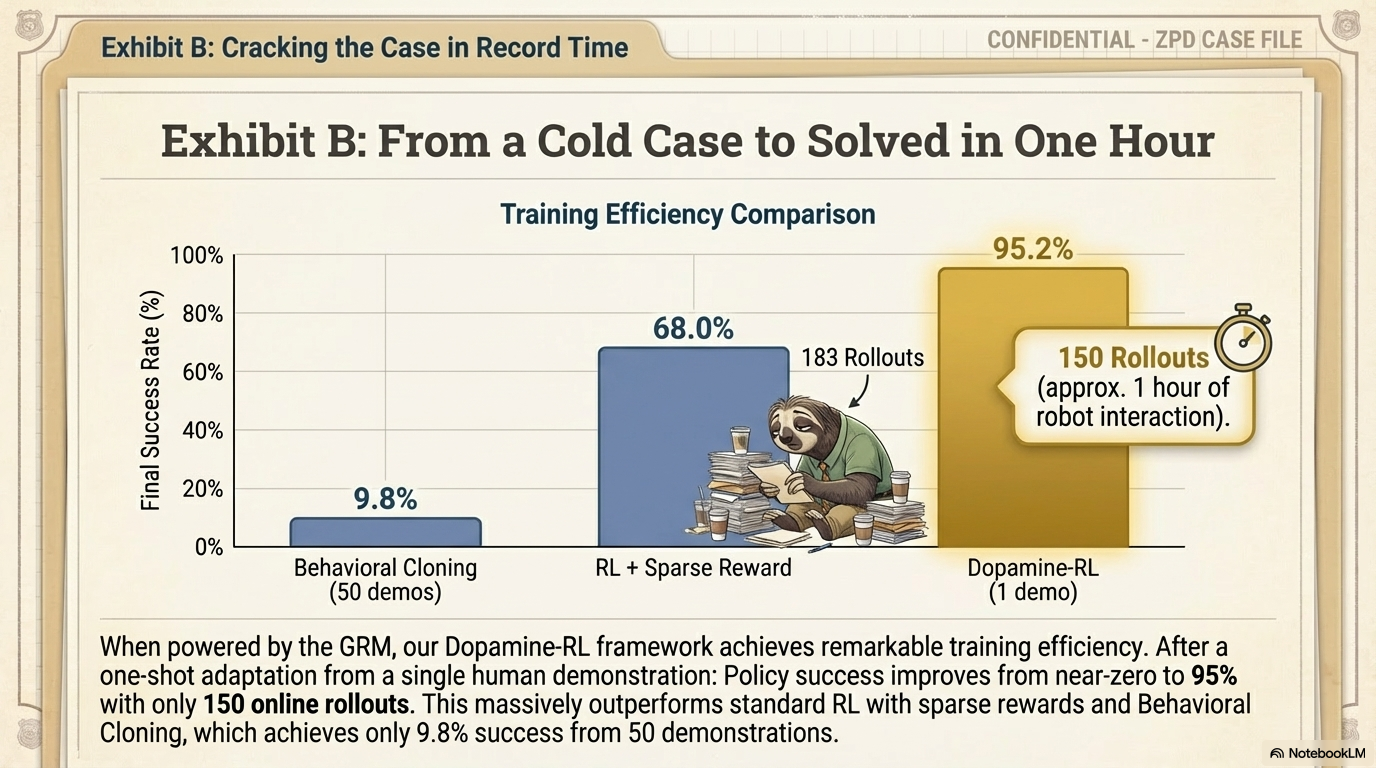


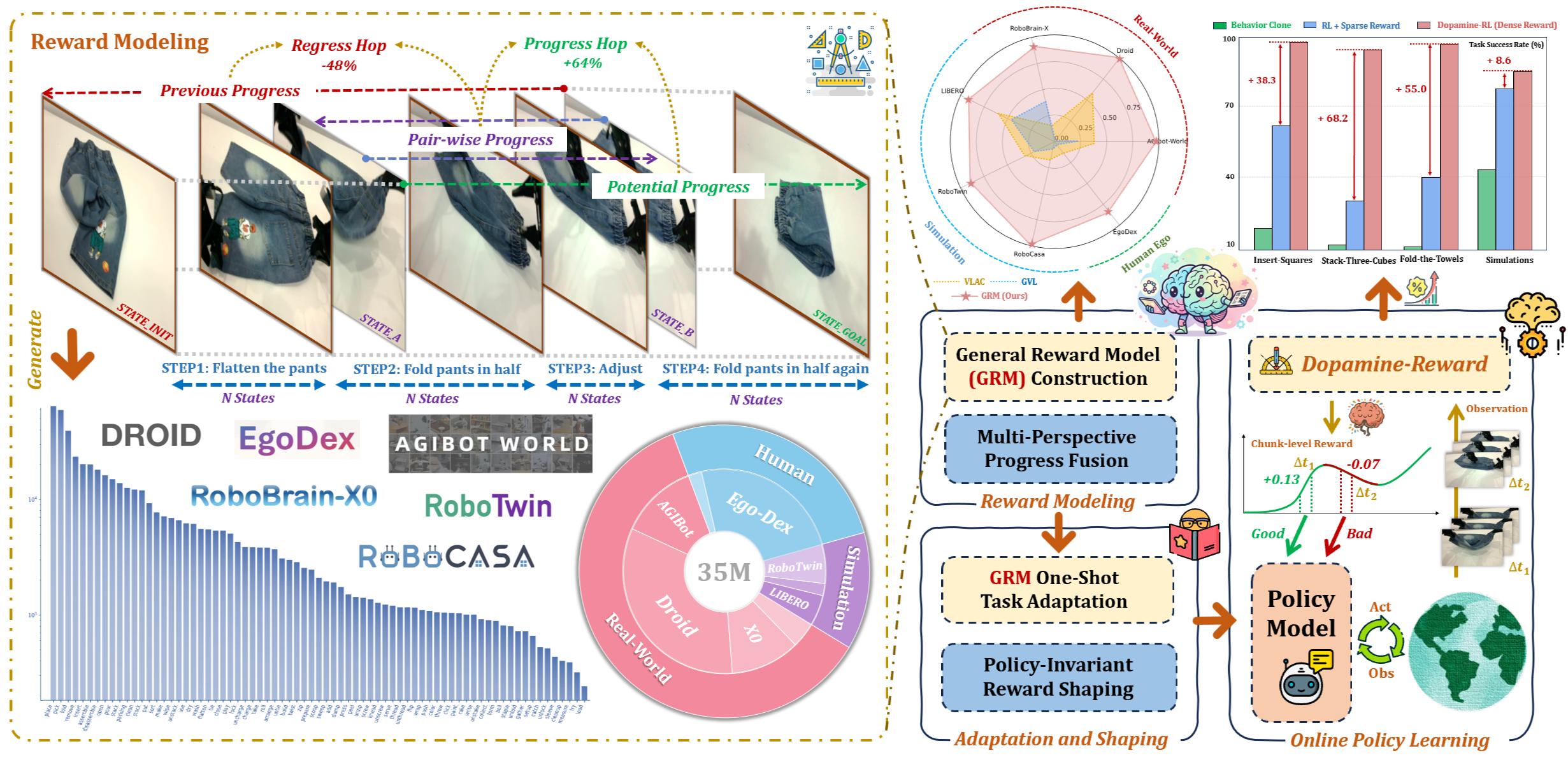
Overview of Robo-Dopamine
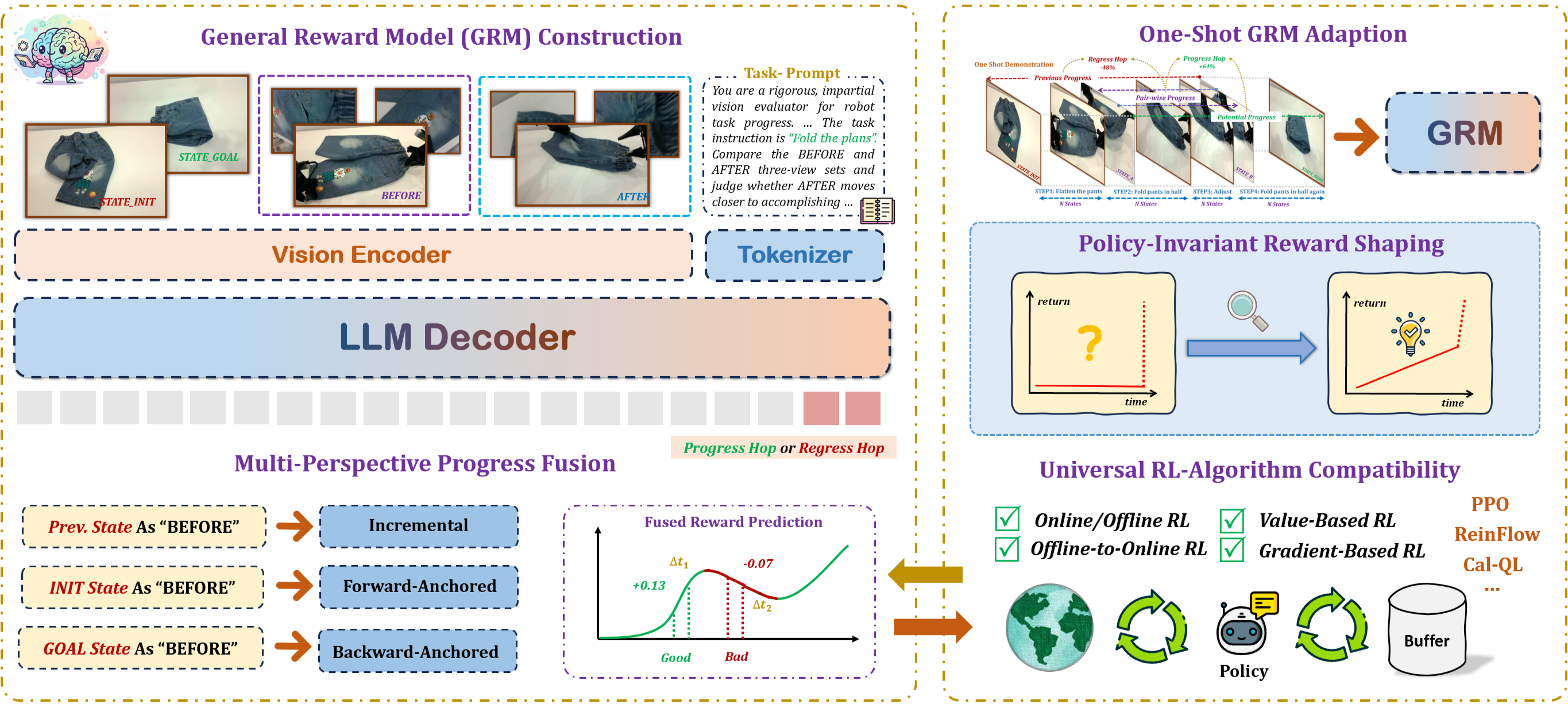
Method of Robo-Dopamine
Overview of GRM Training Data
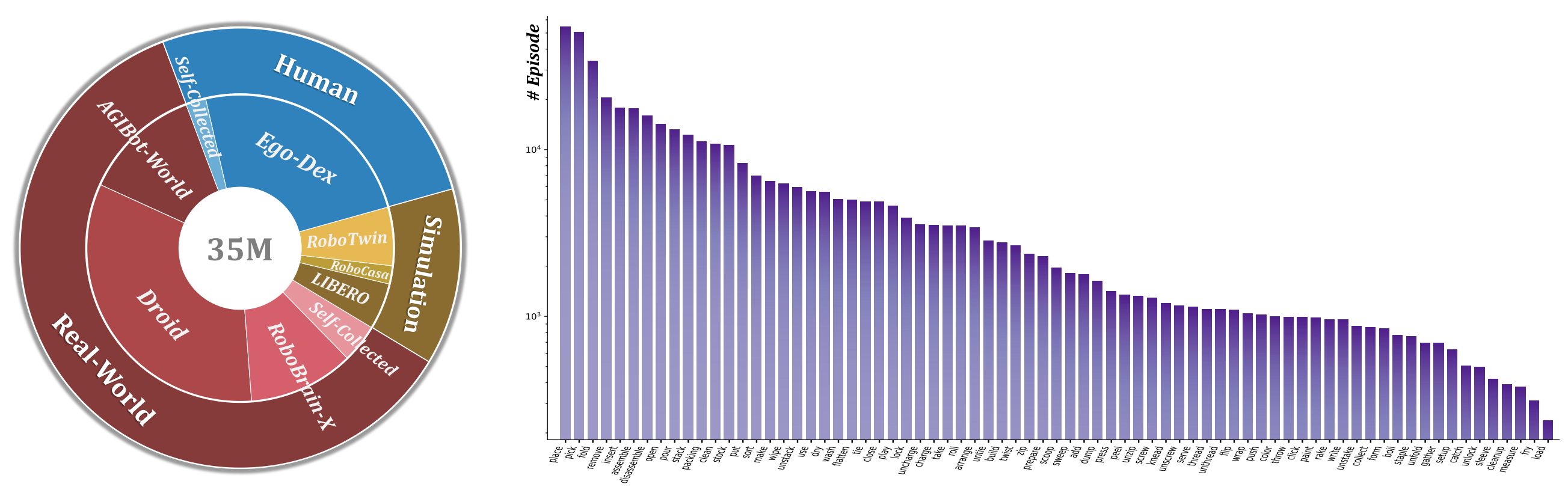
Evaluation on Different Data Sources
Fold the Pants (AgiLex).
Clean the Table (AgiLex).
Fill the Mug (RoboCasa).
Close the Drawer (RoboCasa).
Place Bowl on the Plate (LIBERO).
Open the Drawer (LIBERO).
Stack the Blocks (Flanka).
Stack the Blocks (Human).
Evaluation on Different Sampling Intervals
Sampling Intervals = 100
Sampling Intervals = 50
Sampling Intervals = 25
Sampling Intervals = 10
Analysis on Trajectory VOC and Status Detection

A Challenging Real-world Rollout (Insert Square Block)
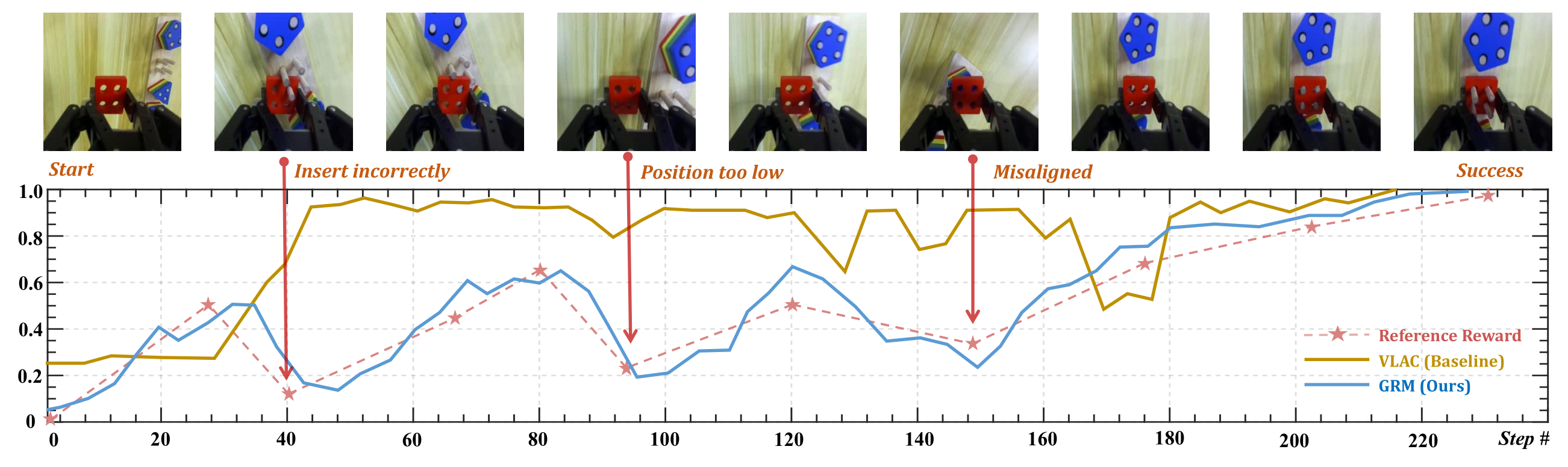
Insert the Square Block.
Trigger the Circuit.
Cap the Pen.
How to Human-in-Loop (Hardware Setup)

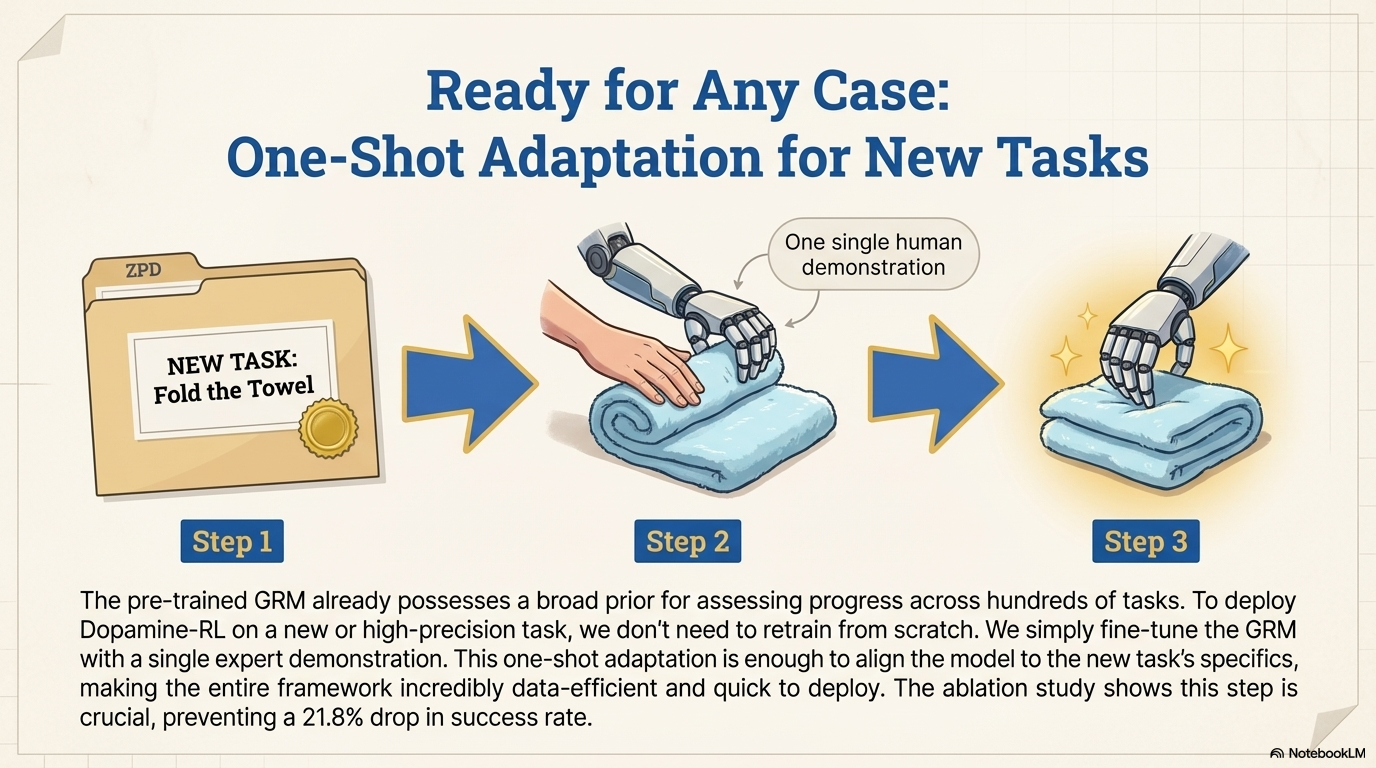
Analysis on Generalization and Efficiency
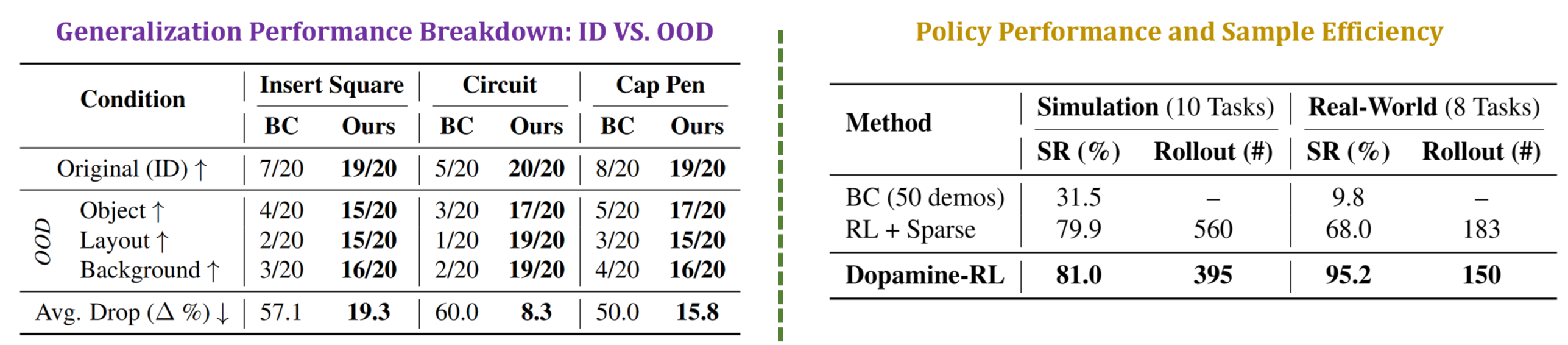
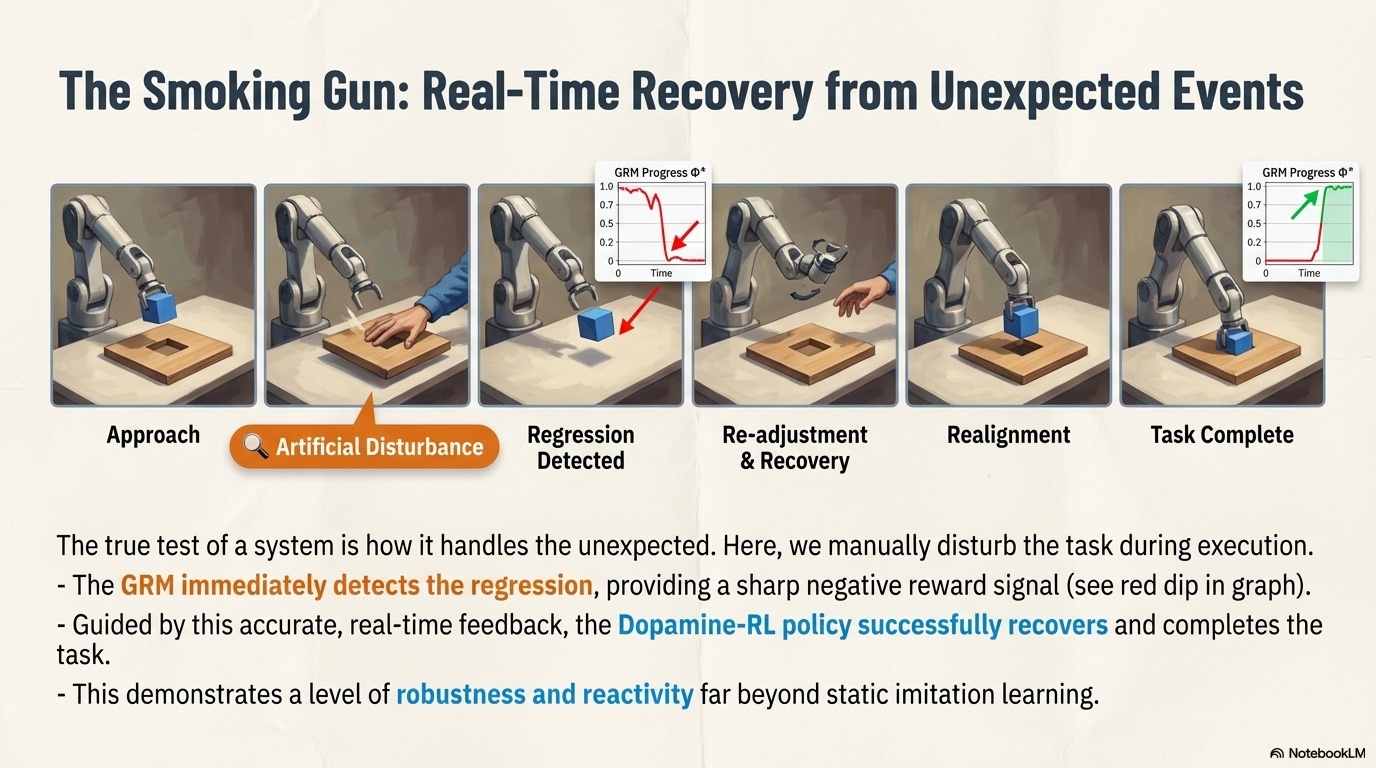
Robustness to Artificial Disturbance

Citation
If you find our work helpful, feel free to cite it:
@article{tan2025robo,
title={Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation},
author={Tan, Huajie and Chen, Sixiang and Xu, Yijie and Wang, Zixiao and Ji, Yuheng and Chi, Cheng and Lyu, Yaoxu and Zhao, Zhongxia and Chen, Xiansheng and Co, Peterson and others},
journal={arXiv preprint arXiv:2512.23703},
year={2025}
}